프록시와 안정적인 트래픽
실제 웹 서비스 환경에서는 수천, 수만 명의 클라이언트가 동시에 요청을 보낸다. 단순한 클라이언트와 서버 사이의 1:1 연결 구조 만으로는 이러한 대규모 요청을 안정적으로 처리하기 어렵다. 따라서 서버와 클라이언트 사이에 중간 계층을 두어 트래픽, 즉 요청과 응답의 흐름을 효율적으로 분산·관리할 필요가 있다. 이 중간 계층은 서버의 과부하를 줄이고, 장애 발생 시 서비스가 중단되지 않도록 하며, 보안이나 성능 최적화까지 담당한다.
트래픽을 관리하는 방법을 이해하기 위해 우리는 오리진 서버와 중간 서버의 개념을 시작으로, 프록시와 게이트웨이가 어떤 역할을 하는지, 또 로드 밸런싱과 스케일링을 통해 서버 자원을 어떻게 안정적으로 운영·확장하는지를 차례대로 살펴보자.
오리진 서버와 중간 서버 & 포워드 프록시와 리버스 프록시
💡오리진 서버 (Origin Server)
- 최종적으로 클라이언트 요청에 대한 응답(자원)을 생성하는 서버
💡중간 서버 (Intermediate Server)
- 클라이언트와 오리진 서버 사이에서 메시지를 주고받으며 트래픽을 관리하는 서버
- ex. 프록시 서버, 게이트웨이, 로드 밸런서 등
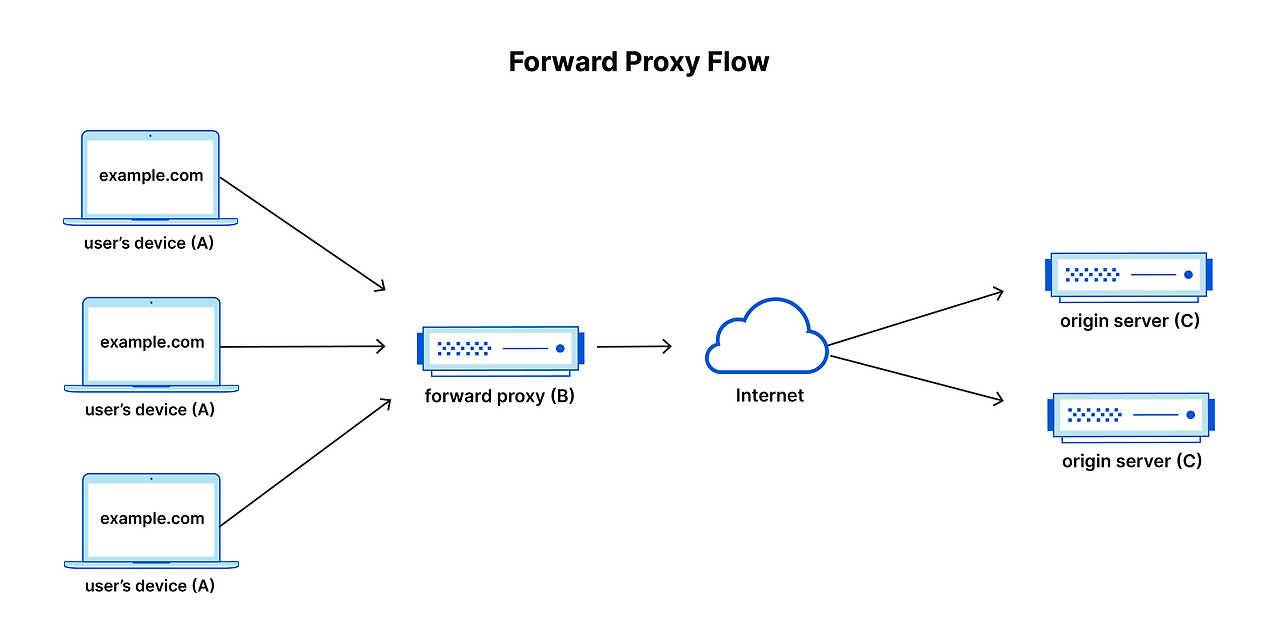
💡프록시 서버 (Proxy)
- 클라이언트와 오리진 서버 사이에서 메시지 전달 대리자 역할
- 주로 클라이언트와 가까운 쪽에서 동작
- 요청을 대신 서버에 전달하거나, 캐시를 저장해 응답 속도를 높임
- 보안·접근 제어 기능도 수행
💡게이트웨이 서버 (Gateway)
- 오리진 서버를 대신해 요청을 받아 응답을 전달하는 서버
- 클라이언트 시각에서는 오리진 서버처럼 보임
- 오리진 서버 앞단에서 경계 역할, 보안·캐싱·로드 밸런싱 등을 담당
고가용성(HA, High Availability)
앞서 살펴본 중간 서버나 트래픽 분산 장치들이 궁극적으로 추구하는 목표가 바로 서비스의 가용성 확보이다. 장애가 발생하더라도 서비스가 멈추지 않고 '항상 동작 가능해야 한다'는 안정성을 수치로 표현한 것이 가용성이고, 서버의 안정성을 높이기 위해서는 가용성 관리가 핵심이 된다.
💡가용성 (Availability)
- 특정 기능이 실제 수행 가능한 시간의 비율
- 시스템 안정성의 기본 지표로 업타임(Uptime) 과 다운타임(Downtime)을 기준으로 측정
- 높은 가용성을 유지하려면 장애 발생 시에도 서비스가 지속되도록 설계해야 함
➡️ 업타임(Uptime) : 시스템이 정상적으로 동작한 시간
➡️ 다운타임(Downtime) : 장애나 문제로 인해 정상 동작하지 못한 시간
➡️ 계산식

- 특정 시스템의 안정성을 평가하기 위해 가용성 수식의 백분율 값을 사용하곤 한다.
- 안정적이라고 평가받는 시스템의 가용성에 대한 백분율 값은 99.999% 이상을 목표로 한다.
| 가용성 (Availability) | 연간 다운타임 | 월간 다운타임 | 주간 다운타임 |
| 90% (원 나인) | 36.53일 | 730.53시간 | 168.8시간 |
| 99% (투 나인) | 3.65일 | 73.1시간 | 16.8시간 |
| 99.9% (쓰리 나인) | 8.77시간 | 43.83분 | 10.08분 |
| 99.95% | 4.38시간 | 21.92분 | 5.04분 |
| 99.99% (포 나인) | 52.56분 | 4.38분 | 1.01분 |
| 99.999% (파이브 나인) | 5.26분 | 26.3초 | 6.05초 |
| 99.9999% (식스 나인) | 31.56초 | 2.63초 | 0.604초 |
| 99.99999% (세븐 나인) | 3.16초 | 0.262초 | 0.0604초 |
- 가용성(Availability) 수치가 9 하나 늘어날 때마다(나인의 개수가 늘어날 때마다) 시스템이 허용할 수 있는 다운타임은 기하급수적으로 줄어든다.
- 99%는 1년에 약 3.65일 서비스가 멈출 수 있다는 의미이고,
- 99.999% (파이브 나인)는 1년에 5분 정도만 다운타임이 허용된다는 의미이다.
💡로드 밸런싱
가용성을 확보하려면 트래픽(요청) 이 한 서버에만 몰려 다운타임이 발생하지 않도록 관리해야 한다. 이를 해결하는 핵심 기술이 바로 로드 밸런싱이다.
✅ 로드 밸런싱 (Load Balancing)
- 클라이언트의 요청을 여러 서버에 균등하게 분산하여 서버 과부하를 방지하는 기술
- 특정 서버에 장애가 발생해도 나머지 서버가 요청을 처리할 수 있어 고가용성 확보에 필수적
➡️ 알고리즘
- 스케일 업 (Scale-up, 수직 확장) : 기존 서버를 더 좋은 성능의 장비로 교체
- 스케일 아웃 (Scale-out, 수평 확장) : 서버 개수를 늘려 부하를 분산
- 오토 스케일링 (Auto-scaling) : 트래픽 증가/감소 상황에 따라 서버 자원을 자동으로 증감
✅ 로드 밸런서 (Load Balancer)
- 다중화된 서버와 클라이언트 사이에 위치하며 클라이언트의 요청들을 각 서버에 균등하게 분배하는 역할은 한다.
💡헬스 체크와 하트비트 (Health Check & Heartbeat)
고가용성을 위해 서버를 여러 대 운영(다중화)한다고 해도, 특정 서버가 장애가 나면 그 서버에 계속 요청을 보내는 것은 전체 서비스 품질을 떨어뜨리게 된다. 따라서 서버가 정상 동작 중인지 감시하고, 문제가 생긴 서버를 자동으로 제외하는 메커니즘이 필요하다. 이 역할을 하는 것이 바로 헬스 체크와 하트비트이다.
✅ 헬스 체크 (Health Check)
- 로드 밸런서나 게이트웨이가 특정 서버에 주기적으로 요청을 보내 해당 서버가 정상적으로 동작하는지 확인하는 과정
✅ 하트비트 (Heartbeat)
- 서버끼리 서로 정기적으로 신호(하트비트 메시지)를 주고받아 살아있음을 확인하는 방식
💡스케일링 (Scaling)
로드 밸런싱으로 트래픽을 분산하더라도, 서버 자원 자체가 부족하다면 안정성을 확보하기 어렵다. 이때 필요한 개념이 바로 스케일링이다.
- 스케일 업 (Scale-up, 수직 확장) : 기존 서버를 더 좋은 성능의 장비로 교체
- 스케일 아웃 (Scale-out, 수평 확장) : 서버 개수를 늘려 부하를 분산
- 오토 스케일링 (Auto-scaling) : 트래픽 증가/감소 상황에 따라 서버 자원을 자동으로 증감
출처
https://www.hanbit.co.kr/store/books/look.php?p_code=B3079890360
이것이 취업을 위한 컴퓨터 과학이다 with CS 기술 면접
기술 면접과 실무에 필요한 CS 지식, 한 권으로 끝내자!
www.hanbit.co.kr
이미지 출처
1) Forward Proxy Flowhttps://www.cloudflare.com/ko-kr/learning/cdn/glossary/reverse-proxy/
'CS > [도서] 이것이 취업을 위한 컴퓨터 과학이다 with CS 기술 면접' 카테고리의 다른 글
| [네트워크] 5-6. (1) 응용 계층 - HTTP의 응용 (0) | 2025.08.21 |
|---|---|
| [네트워크] 5-5. (2) HTTP 메서드와 상태 코드 (3) | 2025.08.18 |
| [네트워크] 5-5. (1) 응용 계층 - HTTP의 기초 (4) | 2025.08.13 |
| [네트워크] 5-4. (1) 전송 계층 - TCP와 UDP (2) | 2025.08.11 |
| [네트워크] 5-3. (1) 네트워크 계층 - IP (3) | 2025.08.07 |